Analyze Finger Tapping Data#
%matplotlib inline
import os
import glob
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
import seaborn as sns
from nltools.data import Brain_Data, Adjacency, Design_Matrix
from nltools.file_reader import onsets_to_dm
from nltools.mask import expand_mask, roi_to_brain
from nltools.stats import regress
from nilearn.plotting import plot_img_on_surf, plot_stat_map, plot_glass_brain, view_img_on_surf
import nibabel as nib
import mne
from mne.io import read_raw_snirf
import mne.io.snirf
from snirf import Snirf
import h5py
from kernel.utils import load_snirf_file, get_resource_path, get_optodes, extract_stimulus_data, pick_channels_from_distance_mne_epochs
mne.viz.set_3d_backend("notebook")
base_dir = '/Users/lukechang/Dropbox/Kernel'
Analyze NIFTI Reconstruction with nltools#
To speed up loading data, we save a resampled version of the data. Alternatively, we could load it in the original 4 x 4 x 4 space like we do using nibabel below.
The nifti reconstructed data has been trimmed to 1 sec before start experiment and 1 sec after experiment end.
We are seeing large scaling differences across regions, so z-scoring data for now, but that means we are losing absolute HbO concentrations
Mask is s k=50 whole brain parcellation based on neurosynth coactivations. Target ROIs correspond to left and right somatomotor cortex
# metadata = {'subject':'S001', 'task_name':FingerTapping', 'task_id':'6f5cbac'}
metadata = {'subject':'S002', 'task_name':'FingerTapping', 'task_id':'387249d'}
# metadata = {'subject':'S004', 'task_name':'FingerTapping', 'task_id':'8f8a587'}
# data_nifti = Brain_Data(os.path.join(base_dir, 'Data', metadata["task_name"], f'Test_{metadata["subject"]}_{metadata["task_id"]}_HbO.nii.gz') )
# data_nifti.write(os.path.join(base_dir, 'Data', metadata["task_name"], f'Test_{metadata["subject"]}_{metadata["task_id"]}_HbO_resampled.nii.gz'))
data_nifti = Brain_Data(os.path.join(base_dir, 'Data', metadata["task_name"], f'Test_{metadata["subject"]}_{metadata["task_id"]}_HbO_resampled.nii.gz') )
data_nifti = data_nifti.standardize(method='zscore')
toffset = nib.load(os.path.join(base_dir, 'Data', metadata["task_name"], f'Test_{metadata["subject"]}_{metadata["task_id"]}_HbO.nii.gz')).header['toffset']
n_tr = len(data_nifti)
mask = Brain_Data(os.path.join(get_resource_path(), 'k50_2mm.nii.gz'))
mask_x = expand_mask(mask)
(mask_x[26] + mask_x[47]).plot()
plt.show()
/opt/anaconda3/envs/mne/lib/python3.11/site-packages/sklearn/preprocessing/_data.py:280: UserWarning: Numerical issues were encountered when scaling the data and might not be solved. The standard deviation of the data is probably very close to 0.
warnings.warn(
/opt/anaconda3/envs/mne/lib/python3.11/site-packages/nilearn/masking.py:980: UserWarning: Data array used to create a new image contains 64-bit ints. This is likely due to creating the array with numpy and passing `int` as the `dtype`. Many tools such as FSL and SPM cannot deal with int64 in Nifti images, so for compatibility the data has been converted to int32.
return new_img_like(mask_img, unmasked, affine)

Create Design_Matrix#
Extract event information and plot average activity within each ROI
events = pd.read_csv(os.path.join(base_dir, 'Data', metadata['task_name'], f'Test_{metadata["subject"]}_{metadata["task_id"]}_task_events.tsv'), sep='\t')
events['timestamp_adjusted'] = events['timestamp'] - toffset
events['block_type'].fillna('rest', inplace=True)
dm = onsets_to_dm(events[['timestamp_adjusted','duration','block_type']].rename(columns={'timestamp_adjusted':'Onset','duration':'Duration','block_type':'Stim'}), sampling_freq=1.0, run_length=len(data_nifti)).drop(columns='rest')
# Generate Plot
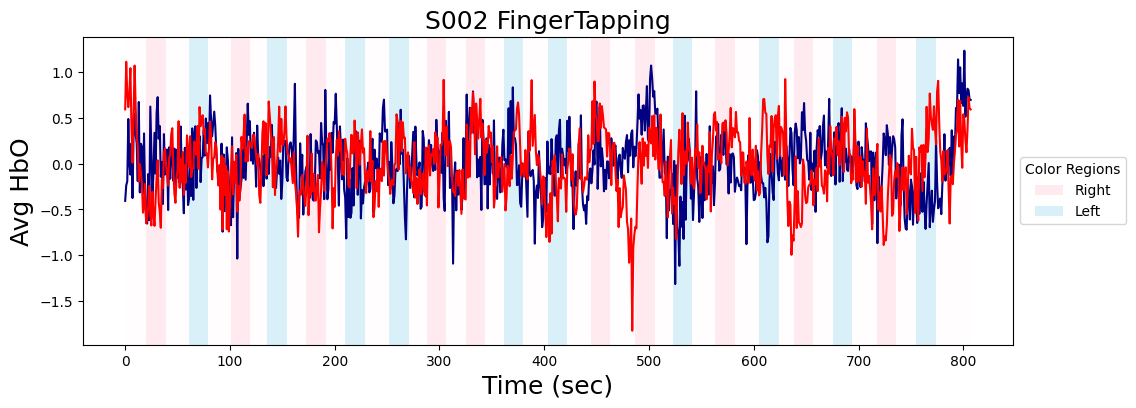
f,a = plt.subplots(1, figsize=(12,4))
left_motor = data_nifti.extract_roi(mask_x[26])
a.plot(left_motor, color='navy')
right_motor = data_nifti.extract_roi(mask_x[47])
a.plot(right_motor, color='red')
# Add colored backgrounds for each integer
colors={'right':'pink', 'left':'skyblue', 'rest':'snow'}
for i,row in dm.iterrows():
if row['right'] == 1:
a.axvspan(i, i+1, facecolor=colors['right'], alpha=0.3)
elif row['left'] == 1:
a.axvspan(i, i+1, facecolor=colors['left'], alpha=0.3)
else:
a.axvspan(i, i+1, facecolor=colors['rest'], alpha=0.3)
a.set_xlabel('Time (sec)', size=18)
a.set_ylabel('Avg HbO', size=18)
legend_elements = [
Patch(facecolor=colors['right'], alpha=0.3, label='Right'),
Patch(facecolor=colors['left'], alpha=0.3, label='Left')
]
a.legend(handles=legend_elements, title='Color Regions', loc='center left', bbox_to_anchor=(1, 0.5))
a.set_title(f"{metadata['subject']} {metadata['task_name']}", size=18)
plt.savefig(os.path.join(base_dir, 'Figures', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_AverageSomatomotorActivity_Experiment.png"), dpi=150)
plt.show()
/var/folders/5b/m183lc3x27n9krrzz85z2x1c0000gn/T/ipykernel_15355/2546783857.py:3: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
events['block_type'].fillna('rest', inplace=True)
/opt/anaconda3/envs/mne/lib/python3.11/site-packages/nilearn/masking.py:980: UserWarning: Data array used to create a new image contains 64-bit ints. This is likely due to creating the array with numpy and passing `int` as the `dtype`. Many tools such as FSL and SPM cannot deal with int64 in Nifti images, so for compatibility the data has been converted to int32.
return new_img_like(mask_img, unmasked, affine)
Run Regression#
Run using nltools 2 x 2 x 2 resampling#
data_nifti.X = dm.convolve().add_dct_basis(duration=100).add_poly(0)
stats_output = data_nifti.regress()
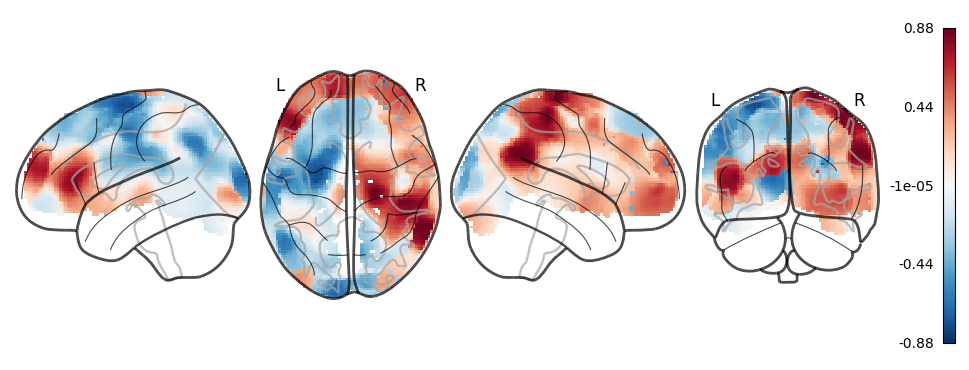
left_v_right = stats_output['beta'][data_nifti.X.columns.str.contains('left')] - stats_output['beta'][data_nifti.X.columns.str.contains('right')]
left_v_right.write(os.path.join(base_dir, 'Analyses', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_LeftVRight_nltools.nii.gz"))
left_v_right.plot(view='glass')
plt.savefig(os.path.join(base_dir, 'Figures', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_LeftVRight_nltools.png"), dpi=150)
plt.show()
Plotting unthresholded image
Run using nibabel 4 x 4 x 4 original sampling#
# Load Data using Nibabel
data_nib = nib.load(os.path.join(base_dir, 'Data', 'FingerTapping', f'Test_{metadata["subject"]}_{metadata["task_id"]}_HbO.nii.gz') )
dat_nib = data_nib.get_fdata()
# dat_nib[data_nib==0] = np.nan
# Run vectorized regression at each voxel
dm_nib = dm.convolve().add_dct_basis(duration=100).add_poly(0)
flattened_dat = dat_nib.reshape(-1, dat_nib.shape[-1])
flattened_dat = ((flattened_dat.T - np.nanmean(flattened_dat, axis=1))/ np.nanstd(flattened_dat, axis=1)).T # z-score
b,se,t,p,df,res = regress(dm_nib, flattened_dat.T)
lvr = b[dm_nib.columns.str.contains('left'),:] - b[dm_nib.columns.str.contains('right'), :]
lvr = nib.Nifti1Image(np.nan_to_num(lvr, nan=0.0).reshape(dat_nib.shape[:-1]), affine=data_nib.affine)
nib.save(lvr, os.path.join(base_dir, 'Analyses', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_LeftVRight_nibabel.nii.gz"))
# Plot glass brain
plot_glass_brain(lvr, cmap='RdBu_r')
plt.savefig(os.path.join(base_dir, 'Figures', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_LeftVRight_nibabel.png"), dpi=150)
plt.show()
view_img_on_surf(lvr, bg_on_data=True)
/var/folders/5b/m183lc3x27n9krrzz85z2x1c0000gn/T/ipykernel_15355/1813066790.py:9: RuntimeWarning: invalid value encountered in divide
flattened_dat = ((flattened_dat.T - np.nanmean(flattened_dat, axis=1))/ np.nanstd(flattened_dat, axis=1)).T # z-score

Create Peristimulus Plot#
events['block_id'] = events['block_type'] + '_' + events['block'].fillna(0).astype(int).astype(str)
dm_block = onsets_to_dm(events.query('block_type != "rest"')[['timestamp_adjusted','duration','block_id']].rename(columns={'timestamp_adjusted':'Onset','duration':'Duration','block_id':'Stim'}), sampling_freq=1.0, run_length=len(data_nifti))
left_blocks = {}
right_blocks = {}
for c in dm_block:
left_blocks[c] = left_motor[dm_block[c]==1]
right_blocks[c] = right_motor[dm_block[c]==1]
shortest_block = np.min([left_blocks[x].shape for x in left_blocks])
left_motor_blocks = pd.DataFrame({x:left_blocks[x][:shortest_block] for x in left_blocks})
right_motor_blocks = pd.DataFrame({x:right_blocks[x][:shortest_block] for x in right_blocks})
left_motor_blocks['Region'] = 'Left Somatomotor'
right_motor_blocks['Region'] = 'Right Somatomotor'
left_motor_blocks['Time'] = left_motor_blocks.index
right_motor_blocks['Time'] = right_motor_blocks.index
blocks = pd.concat([left_motor_blocks, right_motor_blocks], axis=0)
blocks = blocks.melt(id_vars=['Region', 'Time'], var_name='Block', value_name='HbO')
blocks['Condition'] = [x.split('_')[0] for x in blocks['Block']]
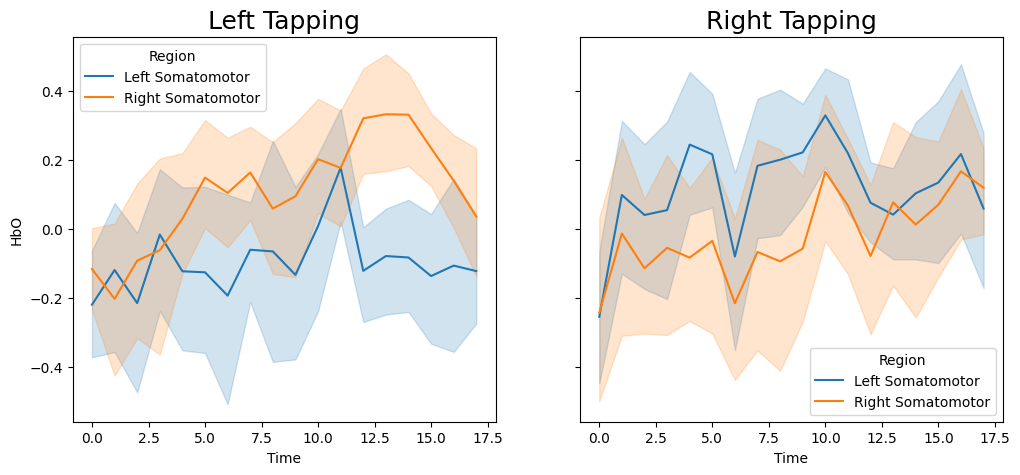
f,a = plt.subplots(ncols=2, figsize=(12,5), sharey=True, sharex=True)
sns.lineplot(data=blocks.query('Condition=="left"'), x='Time', y='HbO', hue='Region', ax=a[0])
a[0].set_title('Left Tapping', size=18)
sns.lineplot(data=blocks.query('Condition=="right"'), x='Time', y='HbO', hue='Region', ax=a[1])
a[1].set_title('Right Tapping', size=18)
plt.savefig(os.path.join(base_dir, 'Figures', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_AverageSomatomotorActivity_Block.png"), dpi=150)
blocks.to_csv(os.path.join(base_dir, 'Analyses', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_SomatomotorActivity_Block.csv"), index=False)
plt.show()
Analyze HB Moments SNIRF#
We will be using functions from MNE to load and analyze the SNIRF data.
Unfortunately, there are a few issues with using MNE.
MNE has not approved a PR to load correct details from Moments or Gates mne-tools/mne-python#9661
MNE does not properly scale the data (raw._data *= 1e-6)
MNE does not properly load data about stimulus events. Currently need to manually access the HDF5 containers
# metadata = {'subject':'S001', 'task_name':'FingerTapping', 'task_id':'6f5cbac'}
metadata = {'subject':'S002', 'task_name':'FingerTapping', 'task_id':'387249d'}
# metadata = {'subject':'S004', 'task_name':'FingerTapping', 'task_id':'8f8a587'}
# Load data
snirf_file = os.path.join(base_dir, 'Data', metadata["task_name"], f'Test_{metadata["subject"]}_{metadata["task_id"]}_5.snirf')
raw = load_snirf_file(snirf_file)
# Get information about each optode
probe_data = get_optodes(snirf_file)
# Apply filter
raw = raw.filter(0.01, 0.1, h_trans_bandwidth=0.01, l_trans_bandwidth=0.01)
Loading /Users/lukechang/Dropbox/Kernel/Data/FingerTapping/Test_S002_387249d_5.snirf
Reading 0 ... 3033 = 0.000 ... 806.778 secs...
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 0.01 - 0.1 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 0.01
- Lower transition bandwidth: 0.01 Hz (-6 dB cutoff frequency: 0.01 Hz)
- Upper passband edge: 0.10 Hz
- Upper transition bandwidth: 0.01 Hz (-6 dB cutoff frequency: 0.11 Hz)
- Filter length: 1241 samples (330.106 s)
[Parallel(n_jobs=1)]: Done 17 tasks | elapsed: 0.0s
[Parallel(n_jobs=1)]: Done 71 tasks | elapsed: 0.0s
[Parallel(n_jobs=1)]: Done 161 tasks | elapsed: 0.0s
[Parallel(n_jobs=1)]: Done 287 tasks | elapsed: 0.0s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 0.1s
[Parallel(n_jobs=1)]: Done 647 tasks | elapsed: 0.1s
[Parallel(n_jobs=1)]: Done 881 tasks | elapsed: 0.1s
[Parallel(n_jobs=1)]: Done 1151 tasks | elapsed: 0.1s
[Parallel(n_jobs=1)]: Done 1457 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 1799 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 2177 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 2591 tasks | elapsed: 0.3s
# Create Events
stim_data = extract_stimulus_data(snirf_file)
stim_name = 'StartBlock'
blocks = stim_data[stim_name]
events, _ = mne.events_from_annotations(raw, {stim_name: 1})
event_dict = {"Tapping/Left": 1, "Tapping/Right": 2}
events[stim_data['StartTrial']['BlockType.Left'] == 1, 2] = event_dict["Tapping/Left"]
events[stim_data['StartTrial']['BlockType.Right'] == 1, 2] = event_dict["Tapping/Right"]
# Create MNE Epochs
tmin, tmax = -5, 45
epochs = mne.Epochs(
raw,
events,
event_id=event_dict,
tmin=tmin,
tmax=tmax,
proj=True,
baseline=(None, 0),
preload=True,
detrend=None,
verbose=True,
)
# Compute Averages for each condition of channels greater than 15mm and less than 30 mm
idx_channels = pick_channels_from_distance_mne_epochs(snirf_file, epochs, min_distance=15, max_distance=30)
left_evoked = epochs["Tapping/Left"].average(picks=idx_channels)
right_evoked = epochs["Tapping/Right"].average(picks=idx_channels)
left_right_evoked = left_evoked.copy()
left_right_evoked._data = left_evoked._data - right_evoked._data
# Create stimulus evoked topoplot
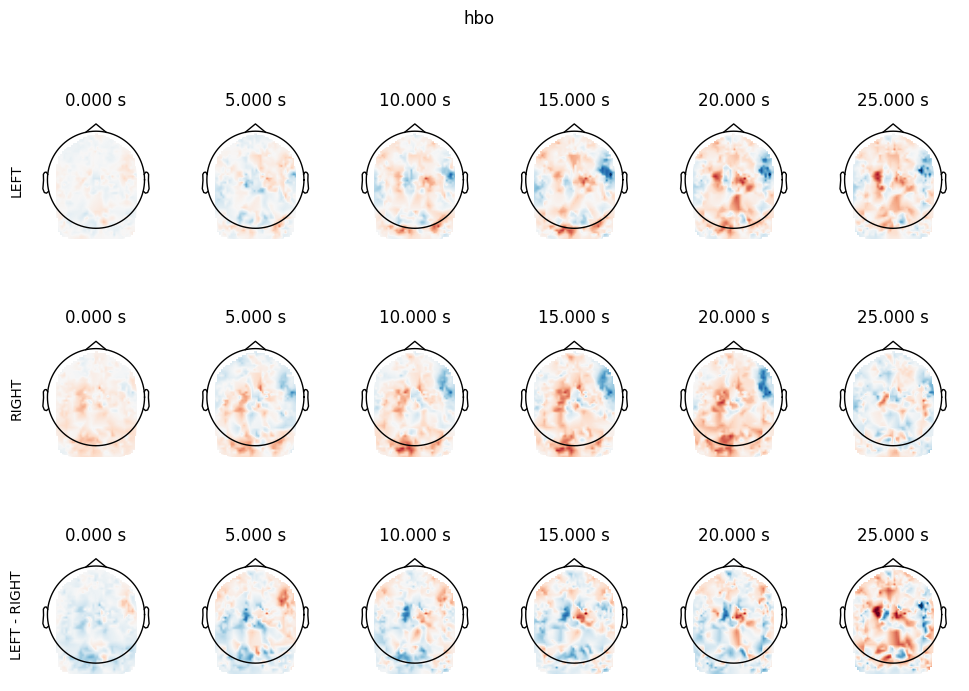
chromophore = "hbo"
times = [0, 5, 10, 15, 20, 25]
vlim = (-7, 7)
plot_topo_kwargs = dict(
ch_type=chromophore,
sensors=False,
image_interp="linear",
vlim=vlim,
extrapolate="local",
contours=0,
colorbar=False,
show=False,
)
fig, ax = plt.subplots(
figsize=(12, 8), nrows=3, ncols=len(times), sharex=True, sharey=True
)
for idx_time, time in enumerate(times):
_ = left_evoked.plot_topomap([time], axes=ax[0][idx_time], **plot_topo_kwargs)
_ = right_evoked.plot_topomap([time], axes=ax[1][idx_time], **plot_topo_kwargs)
_ = left_right_evoked.plot_topomap([time], axes=ax[2][idx_time], **plot_topo_kwargs)
if idx_time == 0:
ax[0][0].set_ylabel("LEFT")
ax[1][0].set_ylabel("RIGHT")
ax[2][0].set_ylabel("LEFT - RIGHT")
fig.suptitle(chromophore)
plt.savefig(os.path.join(base_dir, 'Figures', metadata['task_name'], f"{metadata['subject']}_{metadata['task_name']}_mne_topoplot.png"), dpi=150)
plt.show()
Used Annotations descriptions: ['StartBlock']
Not setting metadata
20 matching events found
Setting baseline interval to [-5.054, 0.0] s
Applying baseline correction (mode: mean)
0 projection items activated
Using data from preloaded Raw for 20 events and 189 original time points ...
0 bad epochs dropped